How to use dummy data in an ehrQL dataset definition🔗
Because OpenSAFELY doesn't allow direct access to individual patient records, ehrQL allows you to work with dummy data for developing analytic code on your own computer.
There are three ways to use dummy data in ehrQL.
Let ehrQL generate a dummy dataset from your dataset definition🔗
ehrQL is designed so that the same command can be used to output a dummy dataset when run on your own computer and then output a real dataset when run inside the secure environment as part of an OpenSAFELY pipeline.
Refer to the documentation on using ehrQL in a study to see how this works.
You do not need to add anything to the dataset definition itself in order to generate a dummy dataset in this way. ehrQL will use the dataset definition to set up dummy data and generate matching patients.
By default, ten patients will be generated in a dummy dataset. If you need to increase this number, you can configure it in the dataset definition with:
dataset.configure_dummy_data(population_size=1000)
 Increasing the population size will increase the time required to generate the dataset.
Increasing the population size will increase the time required to generate the dataset.
Supply your own dummy dataset🔗
You can provide a dummy dataset file in the following formats.
| Format | File extension |
|---|---|
| CSV | .csv |
| Compressed CSV | .csv.gz |
| Arrow | .arrow |
Your dummy dataset file must have the relevant file extension shown in the table
above.
For example, take this dataset definition:
from ehrql import create_dataset
from ehrql.tables.core import patients, medications
dataset = create_dataset()
dataset.define_population(patients.date_of_birth.is_on_or_before("1999-12-31"))
asthma_codes = ["39113311000001107", "39113611000001102"]
latest_asthma_med = (
medications.where(medications.dmd_code.is_in(asthma_codes))
.sort_by(medications.date)
.last_for_patient()
)
dataset.asthma_med_date = latest_asthma_med.date
dataset.asthma_med_code = latest_asthma_med.dmd_code
And this dummy dataset, in a CSV file named dummy.csv:
| patient_id | asthma_med_date | asthma_med_code |
|---|---|---|
| 1 | 2021-01-01 | 39113311000001107 |
| 2 | 2020-03-10 | 39113311000001107 |
| 3 | 2022-11-22 | 39113311000001107 |
| 4 | 2021-06-07 | 39113611000001102 |
| 5 | 2023-10-17 | 39113611000001102 |
Run the dataset definition with the dummy dataset file:
opensafely exec ehrql:v1 generate-dataset dataset_definition.py --dummy-data-file dummy.csv
Now, instead of a generated dummy dataset, you'll see the data from the dummy data file that you provided.
Boolean values🔗
Note that in CSV data, boolean values must be specified as "T" or "F".
Add an extra had_asthma_event to the dataset above:
dataset.had_asthma_event = (
medications.where(medications.dmd_code.is_in(asthma_codes))
.exists_for_patient()
)
This is a boolean value and the updated dummy dataset would look like this:
| patient_id | asthma_med_date | asthma_med_code | had_asthma_event |
|---|---|---|---|
| 1 | 2021-01-01 | 39113311000001107 | T |
| 2 | 2020-03-10 | 39113311000001107 | T |
| 3 | 2022-11-22 | 39113311000001107 | T |
| 4 | 2021-06-07 | 39113611000001102 | T |
| 5 | 2023-10-17 | 39113611000001102 | T |
Dummy dataset errors🔗
ehrQL will check the column names, types and categorical values in your dummy dataset file. If errors are found, they will be shown in the terminal output.
Using ehrQL to generate a base dummy dataset🔗
Generating your own dummy dataset can be difficult (or tedious!), especially if you have a large number of output columns, or you need a large amount of data. One option is to use ehrQL to generate an initial dataset, and then modify it as you need.
Run the dataset definition with an output path:
opensafely exec ehrql:v1 generate-dataset dataset_definition.py --output dataset.csv
Now you can edit dataset.csv as you want, and rerun the dataset definition, using it as the
dummy data file:
opensafely exec ehrql:v1 generate-dataset dataset_definition.py --dummy-data-file dataset.csv
Supply your own dummy tables🔗
Instead of supplying a single dummy dataset file that contains the exact output data, you can provide ehrQL with a path to a folder of dummy data tables. Dummy data tables are supplied as CSV files, with one file per table, representing the data in the backend database. Refer to the table schema reference for documentation on the available tables and columns. ehrQL will use the dummy tables as the backend data from which to extract the dataset. This is a good way to test that your dataset definition is working as expected.
The running ehrQL as a standalone action documentation demonstrates how to to run a dataset definition against the example dummy tables in the ehrQL tutorial.
Generating dummy tables🔗
ehrQL can be used to create dummy tables for you, using your dataset definition to determine the specific tables that are required.
Try this out by running the following command against the simple dataset definition above:
opensafely exec ehrql:v1 create-dummy-tables dataset_definition.py dummy-folder
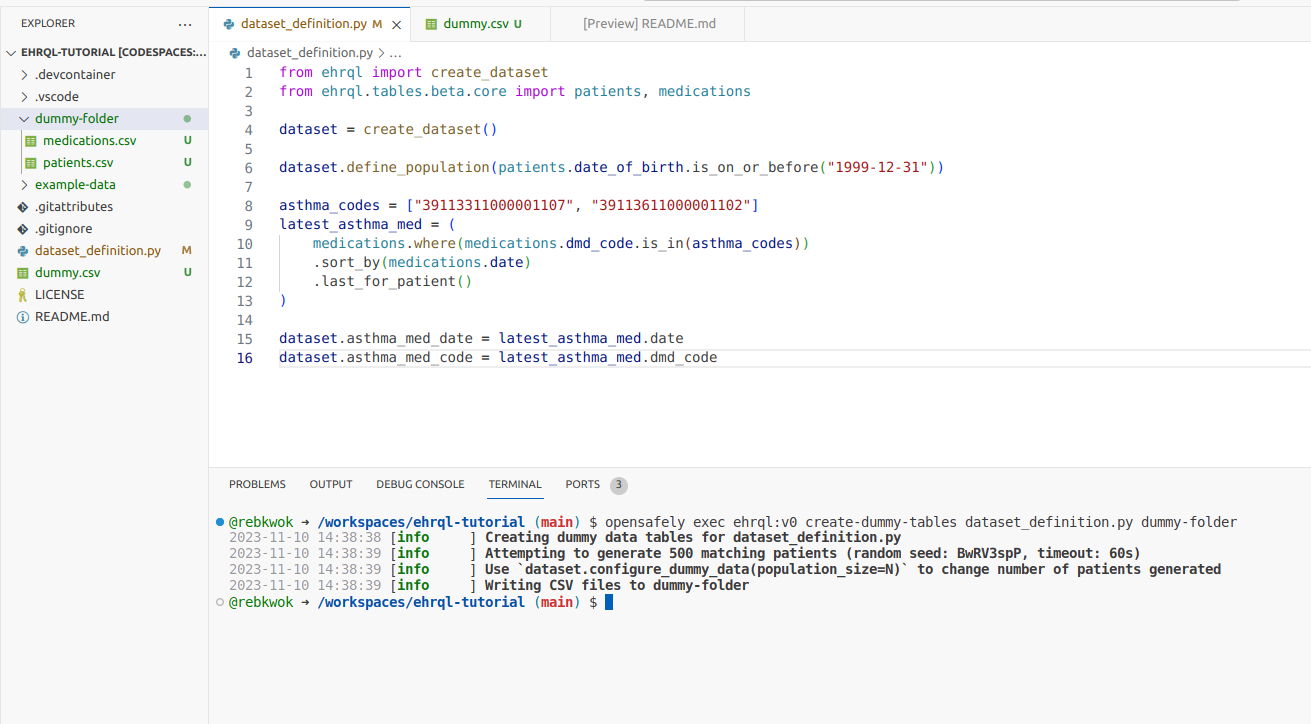
A new folder, dummy-folder, has been created, which contains just the two tables that the
dataset definition requires - patients.csv and medications.csv.
Now you can run ehrQL with these generated tables instead:
opensafely exec ehrql:v1 generate-dataset dataset_definition.py --dummy-tables dummy-folder