Federated analytics
What is federation?
Federation is the ability to write research code for data curation and analysis once; run it in multiple locations that contain sensitive patient data; retrieve summary outputs that have been assured not to contain sensitive data; and combine these outputs.
This means raw clinical data never leaves its original (and secure) location, even when research spans different databases.
The principle of federation is well-established in academic literature, and has been implemented in a number of different clinical research settings, such as EMIF and Personal Health Train.
OpenSAFELY was designed for federation from the start. It is installed as a data access layer in front of multiple existing patient databases; we call an installation a backend. For example, Primary Care data in England is provided by two backends, with the support of the two largest providers of primary care software in the country: TPP and EMIS. In this way, researchers have safe access to the records of nearly 60 million patients in England.
One problem OpenSAFELY solves is that backends may present very different environments and databases: for example, TPP provides their data in a Microsoft SQL Server database on a hardware server, and EMIS provides it via their EXA analytic platform in the cloud. OpenSAFELY tools hide these differences from researchers, so that their code can be run everywhere. After code is run on a backend, its outcomes are carefully checked for safety within the same secure perimeter, and finally released so that they can be recombined:
flowchart LR
code[Single codebase] --> emis[Code executed]
code --> tpp[Code executed]
subgraph securetpp [Secure TPP backend]
tpp --> tppoutputcheck[Output checked]
tppoutputcheck --> tppreleased[Output released]
end
subgraph secureemis [Secure EMIS backend]
emisoutputcheck --> emisreleased[Output released]
emis --> emisoutputcheck[Output checked]
end
tppreleased --> combined[Meta analysis]
emisreleased --> combinedExample walkthrough of federation🔗
We have various examples of completed and published analyses that were conducted using the OpenSAFELY federated analytics tools across 58 million patients’ full GP records. Trends and clinical characteristics of COVID-19 vaccine recipients (British Journal of General Practice, 2022) examines factors associated with having a COVID-19 vaccine. The process for federated analytics is very similar to running OpenSAFELY code in a single setting.
The researcher wrote the code as a single codebase. As with all OpenSAFELY activity, this is composed of small, cross-backend components called actions.
The first action they wrote extracts a dataset using an OpenSAFELY study definition—a uniform way of extracting variables from very different databases. (Note that this example uses cohort-extractor, which has been deprecated in favour of ehrQL. However, this doesn't change the approach to federation.)
For example, this section of the study definition creates a variable that indicates when a patient was most recently recorded as having severe obesity:
sev_obesity = patients.with_these_clinical_events(
sev_obesity_codes,
returning = "date",
ignore_missing_values = True,
find_last_match_in_period = True,
on_or_after = "bmi_stage_date",
on_or_before = "index_date",
date_format = "YYYY-MM-DD",
),
The research tested the code with the version of OpenSAFELY installed on their own computer, and then published their code in GitHub. You can view the above code extract in context.
They then used the OpenSAFELY control panel to request that their code run in both backends. The OpenSAFELY framework converted the study definition to a format understood by each backend's database, executed across the raw patient records, and then retrieved the analysis-ready dataset, making it available for remotely triggered, hands-free processing within the secure backend environment.
Once the data was extracted, the framework automatically executed several more actions which processed it further. The final action was a Cox regression, using (as always) identical code for both backends. The researcher could be confident that the same action would run successfully in both locations, because OpenSAFELY guarantees identical environments everywhere for running code. In this case, for example, the user knew the version of R that they used in local code development would be exactly the same as the version available in the TPP and EMIS backends; and that the data it was processing was identical, because it had been extracted by the same OpenSAFELY tools in each environment.
After execution, the outputs were checked for disclosivity by privacy specialists. When the results of the regression models were validated as safe to release, they were released from the secure backend for direct access by the researcher. You can see the TPP and EMIS outputs for the vaccination paper in their raw form.
Finally, the researcher combined the model outputs from both backends in a meta-analysis with a final script. In this case, they combined model coefficients using inverse-variance-weighting.
Planned work🔗
We always have a range of large and small components under development in OpenSAFELY. In general, we avoid sharing speculative plans and aim to “Show The Thing”. Some examples of new features under development in close collaboration with our users are given below. We are happy to hear feature requests or suggestions from all current or prospective users.
Automated dashboard generation🔗
We are already using the same "write once, run everywhere" federation system to drive operational dashboards, such as our vaccine uptake reports, and our dashboard which monitors the clinical coding of long Covid.
We have also recently launched a prototype of our “point and click” tools to generate cohorts, and dashboards, without needing to write code at all.
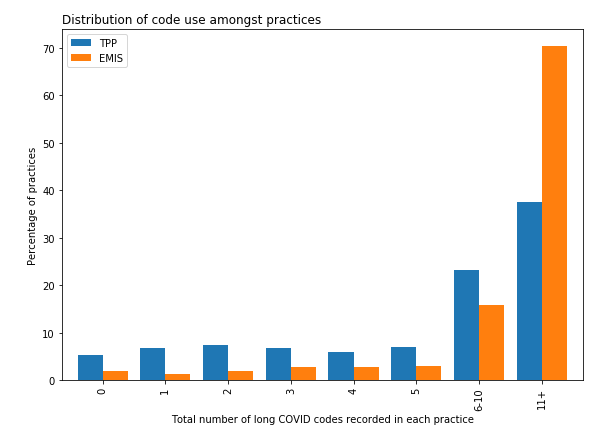
However, the process of publishing dashboards isn't as fast as it could be, mainly because the final step of a federated analysis can only happen after the outputs have been manually checked for disclosivity prior to public release, as in all good Trusted Research Environments. That's why we're focussing on ways to speed up (or even fully automate) some classes of output checking, as part of our OpenSAFELY Interactive project, a no-coding approach to creating templated dashboards.
However, fully automating output releasing is something we don't undertake lightly—there are many risks here, which is why we still maintain humans in the loop at every stage, until we're completely confident we have correctly classified the types of analysis and methods that are safe to use for automatic release.
Automated data linkage🔗
Often, datasets need to be linked at a patient level (for example, when primary care data is linked to hospital data). This unavoidably creates a requirement for moving patient data, which is something we'd like to minimise as far as practical. It also involves several manual steps.
It would be better if raw data were curated using OpenSAFELY tools in situ at the source data centre for each new dataset, and then only the more sparse derived data moved between data centres for linkage, transferring data to the minimum extent necessary for each research purpose. The OpenSAFELY codebase and model are well suited to this way of working, using the methods described above. We have therefore developed a pilot model for this, and will share news as work develops further.
Automated backend selection and combination🔗
At the moment, when a user wants to run code in two backends, they request via the OpenSAFELY dashboard that code be executed in each one separately. This is a small thing, but we'd like to automate the task: it should be possible for a single request to be sent to all supported backends in one go, and scheduled to be run at regular intervals. If we combine this with automated output releasing, it will be possible to develop powerful dashboards that combine data from every OpenSAFELY backend very quickly. For example, we are also developing data curation components that will query every backend for metadata and data quality metrics, and combine them into a single report.
Examples🔗
Trends and clinical characteristics of COVID-19 vaccine recipients: a federated analysis of 57.9 million patients' primary care records in situ using OpenSAFELY British Journal of General Practice https://doi.org/10.3399/bjgp.2021.0376
Recording of "COVID-19 vaccine declined": a cohort study on 57.9 million National Health Service patient's records in situ using OpenSAFELY, England, 8 December 2020 to 25 May 2021 Eurosurveillance https://doi.org/10.2807/1560-7917.ES.2022.27.33.2100885
Potentially inappropriate prescribing of DOACs to people with mechanical heart valves: A federated analysis of 57.9 million patients' primary care records in situ using OpenSAFELY Thrombosis Research https://doi.org/10.1016/j.thromres.2022.01.023
Changes in English medication safety indicators throughout the COVID-19 pandemic: a federated analysis of 57 million patients' primary care records in situ using OpenSAFELY BMJ Medicine https://doi.org/10.1136/bmjmed-2022-000392
Clinical coding of long COVID in English primary care: a federated analysis of 58 million patient records in situ using OpenSAFELY British Journal of General Practice - https://doi.org/10.3399/BJGP.2021.0301
Eleven key measures for monitoring general practice clinical activity during COVID-19 using federated analytics on 48 million adults' primary care records through OpenSAFELY eLife - https://doi.org/10.7554/eLife.84673
The impact of the COVID-19 pandemic on Antipsychotic Prescribing in individuals with autism, dementia, learning disability, serious mental illness or living in a care home: A federated analysis of 59 million patients' primary care records in situ using OpenSAFELY BMJ Ment Health - https://doi.org/10.1136/bmjment-2023-300775
Get in touch!🔗
If you, or a group you know of, are working on federated analytics, we'd love to hear from you at [email protected]. Although we've solved a number of the important federation problems, there's more to do, and we are always seeking collaborators, particularly in the fields of automated output checking, and automated data linkage.